Unit 4: Computer Vision
Hello and welcome to the Computer Vision (CV) section of the I2 megadoc! This section is, due to time constraints, only a very cursory glance at the foundations of CV. This is a whole subfield of ML and even if we spent 10 weeks on it, we wouldn’t scratch the surface!
Let’s start with some motivation. When you look at an image of (for example) a soda can, it does not matter where in the image the soda can is. You are able to detect it and know where it is. This detection ability is called translational invariance. You are able to detect an object even if it has been translated within an image. Traditional DNNs cannot do this (without being heavily overparameterized). Take a second to think about why the architecture of a DNN does not implicitly allow for translationally invariant object classification.
- (Hint: Think about how different the vectorized images would be between the soda can image and its translated invariant. The inputs to the DNN would be drastically different and it would be hard to find any pattern!)
Convolutional Neural Networks (or CNNs) solve this problem and much more. To understand what a CNN is though, you must first understand what a convolution is!
Task: Watch and understand the following videos. We recommend taking notes and being able to answer the synthesis questions provided below. Send your I2 teacher/mentor/overlord the answers to the questions over Discord. Watch up to 13:42 in the video, anything after that is extra information not needed for Deep Learning.
Video: But what is a convolution? (13 min)
Synthesis Questions:
What is the name for the smaller grid that convolves over a larger image?Hint: Starts with a "k"
What are some examples of what you can do to images if you convolve them with special matrices?How does Gaussian blur "work"?What is the name for the actual operation that occurs when the smaller grid is overlaid on the larger one?When each element of the corresponding pixels are multiplied then summed.
Give an example of a 3x3 matrix that would not do anything to the image it convolves over. Why does it not impact the image?This is also known as the "do-nothing" matrix
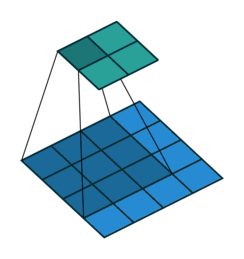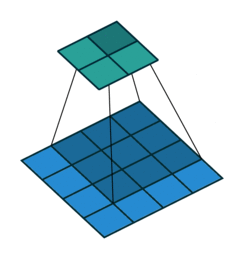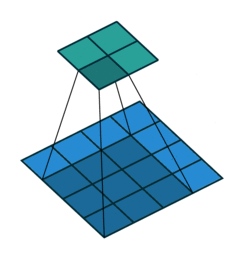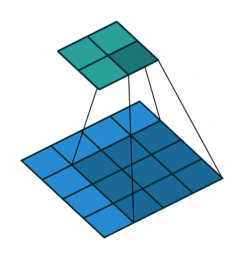
Awesome job! Now we move onto integrating the concept of a convolution into a neural network.
Task: Read the following article, watch the video, and answer the synthesis questions:
Article: Comprehensive CNN Guide (15 min)
Video: Visualizing Convolutional Neural Networks | Layer by Layer (5 min)
Synthesis Questions:
The architecture of a CNN is loosely based on what part of the brain?What is stride length?What is padding?Why is padding useful?
What is the objective of the convolutional layer in a CNN?What is the purpose of the pooling layer in a CNN?What are the two ways to pool shown to you in the article?
What is flattening and when is it done in a CNN?What is the purpose of the feedforward layer in a CNN?How do the convolutional layers before the feedforward layer in a CNN allow for higher accuracy?
We have introduced you to the idea of a convolution and how convolutions are applied in CNNs. Can you begin to see how convolutions help with translational invariance? Think about it for a bit! Before the project, we just want to expose you to a few different types of convolutions. They aren’t all the same and serve different purposes.
Self-Supervised Learning
Human and machines learn in very different ways; think about how you learn new information vs how you gain new experience vs how toddlers learn. Therefore, it is important for us to understand and research different learning approaches. Read the articles listed below and answer the synthesis questions. Don’t focus too much on the math and implementation, focus on getting an intuition. Optionally, watch the video (interview clip) and slides and notebook on variational autoencoders.
Video (optional): Yann LeCun: Self-Supervised Learning Explained (10 min)
Article: Self-Supervised Learning: Definition, Tutorial & Examples (15 min)
Article: Image De-noising Using Deep Learning – Towards AI (15 min)
Article: The brain may learn about the world the same way some computational models do (5 min)
Variational Autoencoder (optional): Variational Autoencoders JC Slides, Notebook
Synthesis Questions:
In short, what is self-supervised learning?What are some short comings of supervised and reinforcement learning?Consider training requirements: data, compute, etcAnd how does self-supervised learning overcome/mitigate these limitations?
How is self-supervised learning similar to human's learning process?How do you think self-supervised learning can be applied to image denoising?Why do you (or do you not) think self-supervised learning is meaningful?
Semantic Segmentation
Our goal with vanilla CNNs was to classify whole images. However, a single image can contain many different objects in different locations. In semantic segmentation, we identify both what is inside an image and where those things are in the image. This is done by classifying each pixel according to pre-defined categories. The first successful architecture for semantic segmentation is U-net. Watch the video below for a high-level understanding of U-net and read the article for more details.
Video: https://www.youtube.com/watch?v=NhdzGfB1q74 Article: https://www.jeremyjordan.me/semantic-segmentation/
Synthesis Questions:
In the U-net architecture, what is the purpose of the downsampling step? What about the upsampling step? Why do skip connections improve the network’s performance?Compare semantic segmentation with human vision. What capabilities could be added to a semantic segmentation model to make it more human-like?
Technical Project Spec:
The project for this “Computer Vision” section will be following the tutorial/Jupyter Notebook below. Please ask questions in the discord as you work through this project. Be sure to discuss with others in your group!
A few general helpful tips (if applicable):
- Be sure to appropriately make a copy of the Colab template before starting to save your progress!
- Renaming your copy to something that contains your name is a good idea, it will make it easier for us to review your submissions.
- Leave comments to cement your understanding. Link syntax to ideas.
- Read up on what CIFAR-10 is.
Now, follow the instructions on this Jupyter notebook to implement some of the things we talked about. There is an “answers” link at the bottom of the notebook that you can use if stuck. You will need to download the ‘.ipynb’ found in that directory and open it either locally or in a new colab project yourself. Ask around if you are unable to get it working!
Colab Link: Unit 4 Notebook (1 hr)
When you are finished with your code, independently verify that it works and have fun with it! If you add any additional functionality be sure to talk about it with others and give them ideas.
Remember that this is all for your learning, so do your best and don’t stress!
Congratulations! You now understand the basics of Convolutional Neural networks!
Non-Technical Project Spec:
The non-technical project for this unit will involve some writing! Choose 3 of the prompts below and write at least 200 (meaningful!) words on each one! We will not be strictly grading you on correctness or anything like that. This is an opportunity to deeply engage with the material you have just learned about, and creatively connect it to neuroscience!
- How are CNNs inspired by the human visual system?
- What are some similarities and differences between CNNs and the human visual system?
- How is the pooling layer in CNNs related to the brain’s visual processing?
- What ways does the convolutional layer in CNNs resemble the receptive field in the visual system?
- Reflecting on you have learned from this unit, what is one thing you found to be most interesting?
- What is one concept from this unit that you would like to learn more about and why?
Be sure to submit your work through google drive using the submission form! We would prefer that you upload it to your own Drive first, then use the submission form dropbox to connect that file to your submission!