Unit 6: Reinforcement Learning
Hello and welcome to the Reinforcement Learning (RL) section of the I2 megadoc! Reinforcement learning is an incredibly powerful subfield of Machine Learning that can be used to deploy intelligent autonomous agents in both real and simulated systems. Reinforcement learning in itself is not inherently tied to AI. It is its own field that has strong ties to probability and statistics theory.
For the purposes of simplicity, we will only cover the very basics and terminology of Deep RL (RL combined with deep learning). Just as a heads up, RL is probably one of the most “deep” and currently relevant subfields of ML, followed closely by language modeling (this may also be the Dunning-Kruger effect, RL is what I have the most expertise on). Folks at OpenAI have compiled a plethora of resources for Deep RL and Deep RL research. We will show you the most relevant articles they have published but they have a wealth of knowledge to learn! Feel free to poke around on the Spinning Up page in your own time.
Task: Read the Key Concepts in RL section of the Spinning Up Intro to RL page. This is a short, but dense article. (45 min)
You may skip the section on Diagonal Gaussian Policies.
Synthesis Questions:
In what situations do we use reinforcement learning? What kinds of problems does it solve?Give an example of RL used to play a game. Did it outperform humans? Does this scare you?
What do the variables s, a, τ, represent in RL?What do s', a' represent?
What is an action space?What is an episode?How is a neural network used to generate a probability distribution over actions given a state?(i.e How would you construct a network if the dimensionality of the state was n1 and the action space had a cardinality of m1)How is the log probability calculated from the logits of the NN output?Note: This is called an actor NN!
Describe infinite-horizon discounted return and what the discount factor isDescribe what a stochastic policy is (you may have to look up what stochasticity is), and what it means for a policy to be parameterized by θWhat is a good policy looking to maximize?Think: If you set up your rewards in your environment randomly, would an RL model learn anything? No. This ties into the greater idea of reward-shaping, which is the concept of how to place rewards in an environment to encourage "good" behavior by an RL agent.
What is the difference between the value function and the Q-function?Describe the connection between the two
Based on the idea behind Bellman Equations ("The value of your starting point is the reward you expect to get from being there, plus the value of wherever you land next.") Explain how the following two equations satisfy the idea behind Bellman Equations:

This may help:

What is the advantage function?
This was a lot of content. Good job on getting through it all! Reinforcement learning is quite a math heavy subfield. Get used to a whole lot of probability and integration. Spelling out exactly what the equations are doing (by reading them out loud) can help quite a bit. Next we will be diving into some in-practice algorithms on a high level.
So, in general, these equations that you have learned about are ideals, not what is done in practice. What generally happens with deep learning RL algorithms is that these functions are **approximated ** by a neural network rather than calculated. This is important to keep in mind as you go on, because a lot of these equations have some recursiveness to them and often have such a huge search space that finding the perfect parameters for V* or Q* is near impossible in complex environments.
Task: Read the “Kinds of RL Algorithms” section of the Spinning Up Intro to RL page. (15 min)
You may skip the section on What to Learn in Model-Based RL
Synthesis Questions:
What is the difference between model-free and model-based RL?What is the difference between policy approximators and Q-learning?Think back to what the J(π) function was. How would performing gradient ascent (finding where this function is locally highest) on this function help the agent perform well in its environment?How is a policy derived (not literally a derivation) from the Q-function? Hint: argmax
Great job on completing the tasks!
The last thing I will talk about before the project is the concept of epsilon-greediness for Q-learning. In essence, argmaxing the Q-function can lead to being stuck in a “pocket” where the agent gets stuck taking the same few trajectories due to the deterministic selection of the action to take. Since Q-learning is usually model-free, there is no way to “see” what lies beyond what is explored. Since the model will not take the actions to explore these trajectories, possibly more efficient solutions cannot be stumbled on by chance. This is where epsilon greediness comes in. With probability ε, the policy will take a random action rather than the one that maximizes the Q-function. ε starts off large and diminishes over time, as the model is expected to have learned better by then and there is less need to explore rather than exploit the learned model for high returns. You can see how epsilon changes through episodes in the graph below.
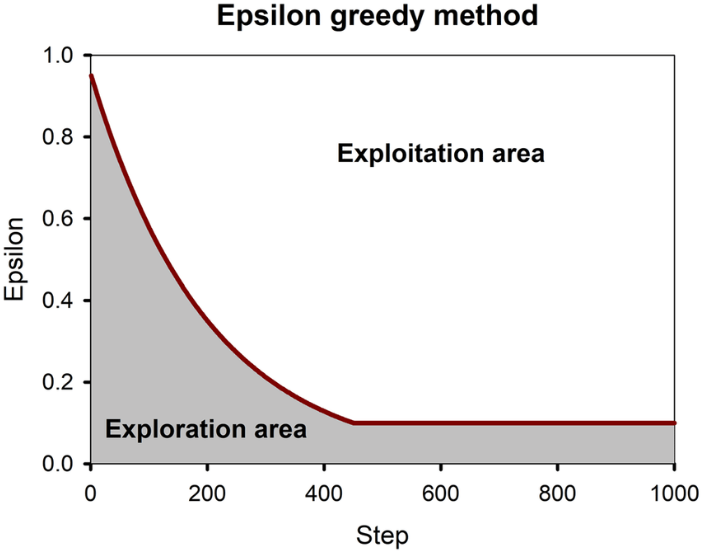
You can read more about epsilon-greedy algorithms in this article (Section 5.2). It works quite well and often gets a model “unstuck” from optimizing poorly through not exploring.
Technical Project Spec:
The project for this “Reinforcement Learning” section will be following the tutorial/Jupyter Notebook below. Please ask questions in the discord as you work through this project. Be sure to discuss with others in your group!
A few general helpful tips (if applicable):
- Be sure to appropriately make a copy of the Colab template before starting to save your progress!
- Renaming your copy to something that contains your name is a good idea, it will make it easier for us to review your submissions.
- Type most of the code out yourself instead of just copying from the tutorial.
- Leave comments to cement your understanding. Link syntax to ideas.
Now, follow the instructions on this Jupyter notebook to implement some of the things we talked about. There is an “answers” link at the bottom of the notebook that you can use if stuck. You will need to download the ‘.ipynb’ found in that directory and open it either locally or in a new colab project yourself. Ask around if you are unable to get it working!
Colab Link: Unit 6 Notebook (1.5 hr)
When you are finished with your code, independently verify that it works and have fun with it! If you add any additional functionality be sure to talk about it with others and give them ideas.
Remember that this is all for your learning, so do your best and don’t stress!
Congratulations! You now understand the (incredibly basic) basics of Deep RL!
Non-Technical Project Spec:
The non-technical project for this unit will involve some writing! Choose 3 of the prompts below and write at least 200 (meaningful!) words on each one! We will not be strictly grading you on correctness or anything like that. This is an opportunity to deeply engage with the material you have just learned about, and creatively connect it to neuroscience!
- Can you provide examples of experimental evidence linking reinforcement learning algorithms to observed synaptic changes in the brain?
- How do human neural systems encode reward signals and how does this relate to the concept of rewards in reinforcement learning models?
- What ethical considerations should be taken into account when developing interventions based on neuroscientific findings, and how can accountability be established for the potential impacts of such interventions?
- Reflecting on you have learned from this unit, what is one thing you found to be most interesting?
- What is one concept from this unit that you would like to learn more about and why?
Be sure to submit your work through google drive using the submission form! We would prefer that you upload it to your own Drive first, then use the submission form dropbox to connect that file to your submission!